Both dedicated storage arrays and vSAN are vulnerable to catastrophic failures, and using backups for storage failure recoveries may put your organization at risk. The problem is that many organizations rely solely on backups to recover from data loss, but what happens when your RAID system or entire storage infrastructure fails?
Traditional backup and disaster recovery strategies assume that storage remains operational. However, when faced with a multi-drive RAID failure or complete storage system failure, these assumptions fall apart, leaving IT scrambling for a way to restore critical applications.
The Multi-Drive RAID Failure Problem
RAID provides redundancy, but it is not immune to failure. If multiple drives fail in a RAID system, the array enters rebuild mode, which can take hours or even days, depending on the system and disk sizes. The greater the number of modern high-capacity drives used in today’s storage infrastructures is, the longer the rebuilds take. During this time, performance is severely degraded if the system remains online. In worst-case scenarios, additional failures during a rebuild can result in total data loss, requiring a full recovery from backups.
Recovering from a backup introduces another challenge: backup frequency. If backups only run once per night, the most recent recovery point may be nearly 24 hours old. That means a business day’s worth of transactions, work, and updates could be permanently lost. Even so-called instant recovery solutions provide only a temporary stopgap. These solutions run in an emulated mode on the backup storage appliance, which lacks the performance required to support production workloads. Once IT initiates recovery, data must be migrated back into production, which can only happen after the primary storage system is back online. If the failed RAID system takes days to rebuild, business operations remain at a standstill.
What Happens When an Entire Storage System Fails?
If the storage system fails due to controller failure, power supply issues, firmware corruption, or catastrophic hardware damage, the problem is significantly worse. With RAID failures, at least some storage remains intact. A total storage system failure means there is nowhere to restore the backup.
Even with a high-end storage vendor’s four-hour response time, that only guarantees a technician will arrive to diagnose the issue within four hours. The technician must still determine the failure, replace the necessary components, and return the system online. If new storage hardware is required, IT may need to procure and deploy new components, adding days or weeks to recovery time.
Traditional Recovery Strategies Are Insufficient
Using backups for storage failure, even with frequent backups, the backup interval limits the best-case recovery scenario. If the system only performs nightly backups, the most recent 24 hours of data are lost even after a complete restoration. Additionally, backups are designed for restoration and are not available continuously.
Bringing production storage back online still requires:
- Provisioning and initializing new storage
- Mounting and reformatting volumes
- Transferring terabytes or petabytes of backup data back into production
- Verifying data consistency and restoring application dependencies
Even backup solutions advertising “instant recovery” will not eliminate downtime. First, the data is still from last night’s backup, meaning any work completed throughout the day is lost. Second, “instant recovery” is not actually instant. The process still takes 30 minutes or more to complete, during which time workloads remain inaccessible.
Worse yet, most backup appliances are not designed for production workloads. These solutions run in an emulated state on the backup storage system, which lacks the performance characteristics needed to support live applications.
A critical factor often overlooked with instant recovery is migration back to production storage, which cannot occur until the primary production system is back online. If the storage system remains down or is undergoing lengthy repairs, the recovered environment remains trapped in the backup appliance, unable to transition to full production. This migration challenge significantly extends downtime and leaves IT with no viable path to restore normal operations until storage and production workloads are fully rebuilt.
VergeIO’s Inline Recovery with ioGuardian
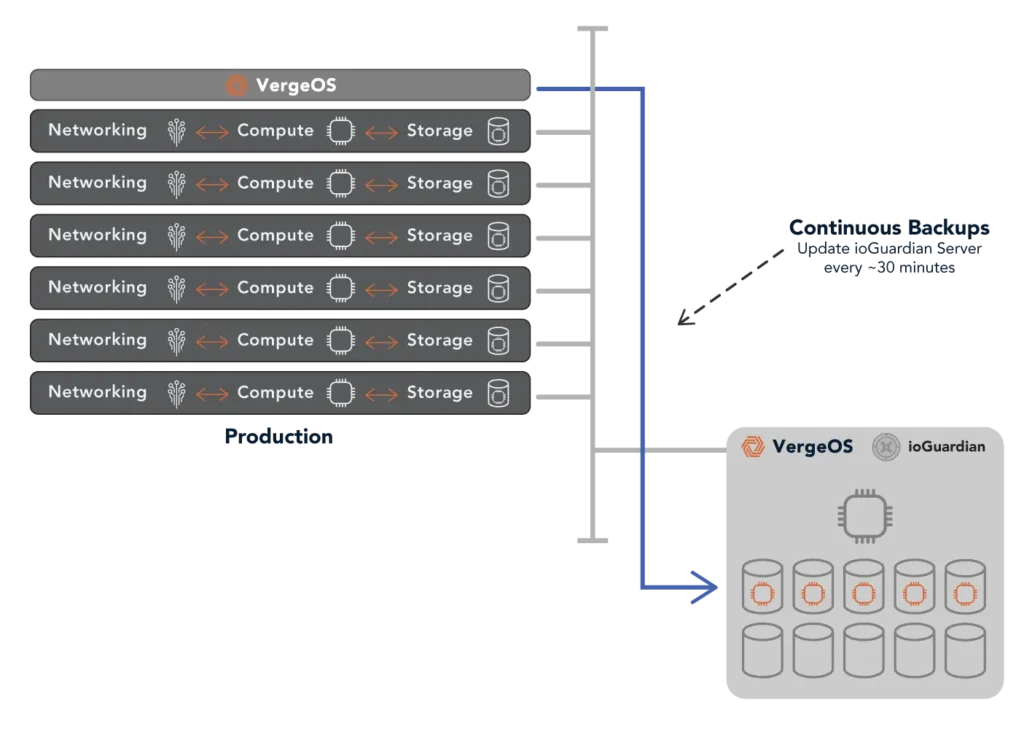
Instead of using backups for storage failure, VergeIO provides an inline repair capability built into the core of VergeOS, ioGuardian. Instead of relying on slow and complex backup restores, VergeOS frequently replicates to another, cost-effective storage instance, enabling instant inline recovery without requiring external backups.
Unlike RAID, which requires lengthy rebuilds and backup solutions that rely on outdated backups, VergeOS dynamically reallocates data blocks to workloads at the moment of failure, ensuring that applications remain operational. Even during multiple simultaneous drive or server failures, VergeIO can keep systems online—without waiting for RAID to rebuild or backup storage to be manually restored.
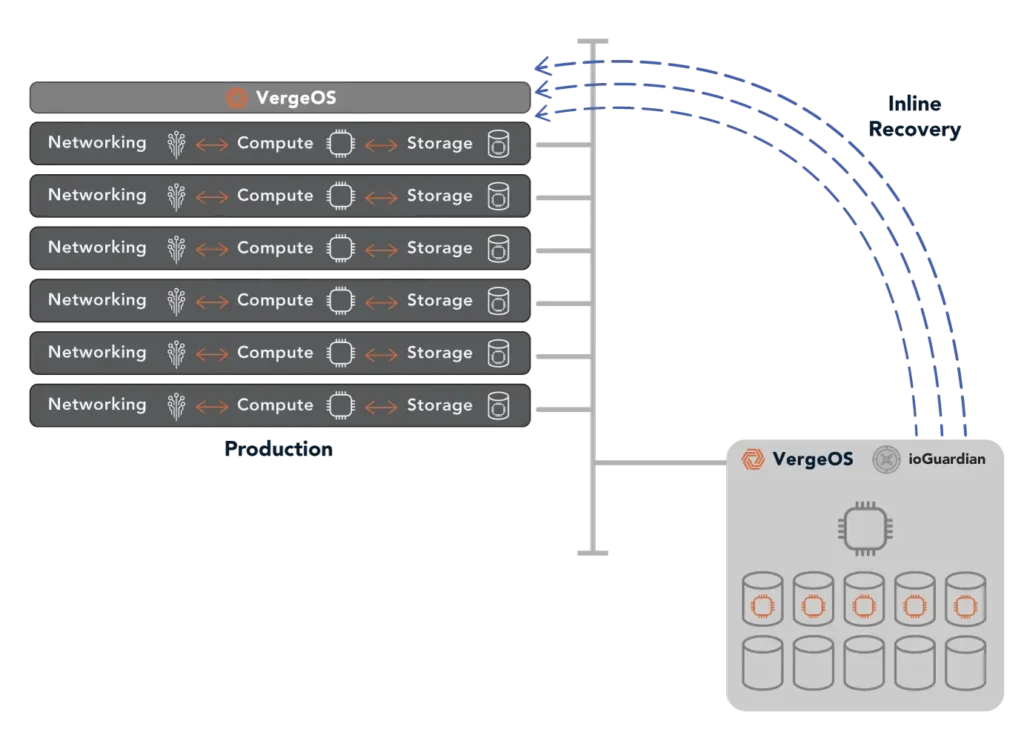
This capability was demonstrated in our recent webinar comparing vSAN alternatives, where we successfully recovered from multiple concurrent drive failures in real time without performance degradation.
Rethinking Storage Resiliency
Using backups for storage failure is no longer the only, or even the best approach. Traditional backup and recovery models assume that storage will always be available to restore data; this includes instant recovery. That assumption no longer exists in modern IT environments, where storage failures can result in prolonged downtime. The only way to guarantee continuous operations is to integrate recovery directly into the vSAN and the hypervisor.
With VergeOS and ioGuardian, IT teams can confidently deploy commodity hardware without worrying that hardware failures—even multiple simultaneous failures—will impact production operations. This is how a VMware alternative like VergeOS can be more than just a VMware alternative—it delivers superior data resiliency that legacy hypervisors and storage systems simply cannot match.