VergeOS can provide complete layer 2 and layer 3 functionality! This video shows you how to tap into the full potential of VergeOS’ networking capabilities. Our latest LightBoard video features CEO Yan Ness and Director of Product Development Paul Hodges, taking you through VergeOS Networking Fundamentals.
VMware Scale Comparisons

During our “InBrief” Event with Truth In IT, one of the most frequently asked questions was about VMware scale comparisons. This series of questions moved beyond the more general Comparing VMware to VergeOS and focused specifically on how VergeOS handles the demands of scale compared to VMware.
To learn more about VergeOS’ scaling capabilities, watch our on-demand webinar “How to Eliminate the Data Center Scale Problem.”
Understanding VMware Scale Methods
Before making any VMware scale comparisons, you must understand its scaling methodology. How VMware scales depends mainly on the infrastructure on which it resides. Most VMware environments use the classic three-tier architecture with physical network switches, servers, and a separate storage system. Most organizations have one primary switch and server vendor, although a few alternate brands may be in use. However, the storage tier, especially as the environment scales, typically has multiple storage systems for different virtual machine (VM) types or use cases.
A less popular alternative is the classic hyperconverged infrastructure (HCI) which loads software-defined networking (SDN) and software-defined storage (SDS) software onto the same nodes as VMware ESXi. In most cases, the SDN and SDS software run as VMs and are subject to ESXi capabilities. As a result, the organization still has a three-tier architecture. It is just that those tiers are now logical instead of physical. This logical representation of the three-tier architecture is why the classic three-tier architecture remains so prevalent.
These two infrastructures impact the scalability of VMware. VMware claims to support 96 nodes per ESXi cluster in the classic three-tier architecture, but only 64 nodes within its HCI cluster because of limitations within the vSAN cluster.
Understanding VergeOS Scale Methods
VergeOS is an ultraconverged infrastructure (UCI). Similar to HCI, it does not use an external storage array. Unlike HCI’s use of separate SDN and SDS software inside the hypervisor, UCI integrates the networking and storage functionality into the hypervisor. This critical difference significantly improves the ability to scale the infrastructure, especially when you compare UCI to HCI. There is no technical limit on the number of nodes VergeOS support, and there is no case of “diminishing returns” as you scale. We have customers in production with over 60 active nodes in a single VergeOS instance.
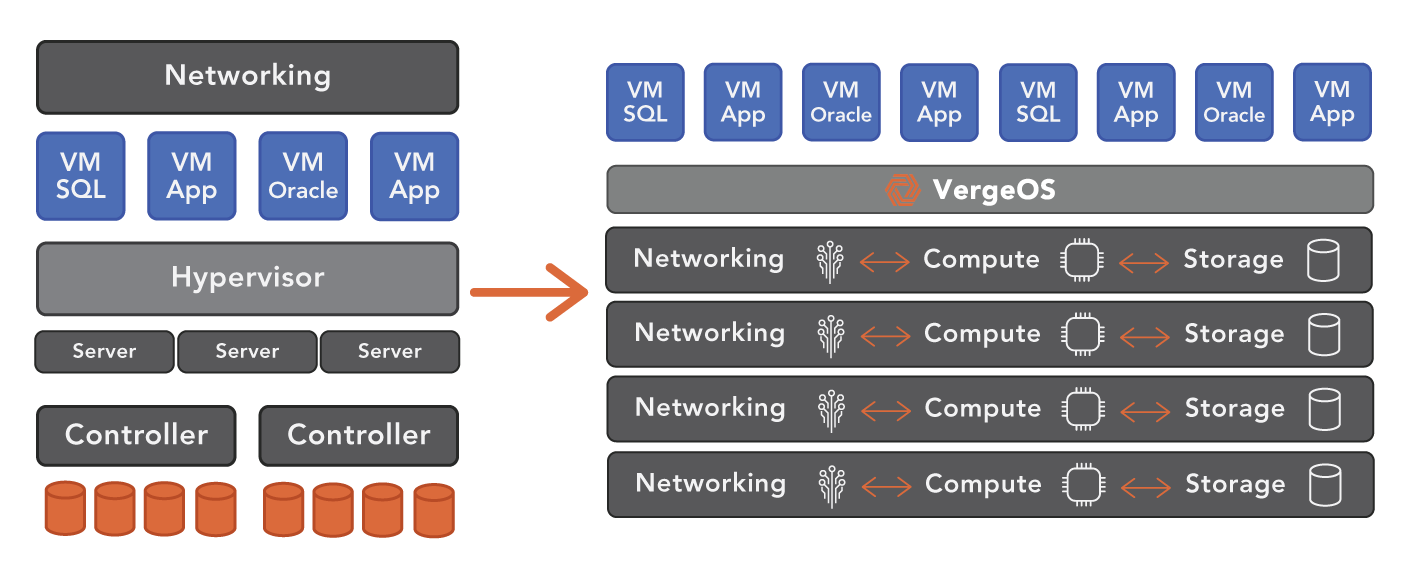
Subscribe to our Digital Learning Guide (DLG), “Understanding the VergeOS Architecture,” for a deep dive into our ultraconverged infrastructure. Our DLGs are white papers delivered in weekly bite-sized chunks.
Comparing VergeOS to VMware Scale
When making VMware scale comparisons, there are two aspects to remember. First, what are the technical limitations of scalability, and second, what are the ramifications of scaling the cluster on resource utilization and organizational flexibility?
VergeOS’ Technical Scale is Better Than VMware Scale
VergeOS is superior in raw node count versus VMware, enabling large enterprises to meet even the most demanding processing and storage performance requirements. Again, we have production customers with over 60 nodes, hundreds of virtual data centers, and thousands of virtual machines. These customers have been running VergeOS at this level of scale for years. VergeOS customers also don’t need to worry about scaling complexity. With VergeOS, there is only one software package, not three or more.
VergeOS’ Efficient Scale is Better Than VMware Scale
VMware scale comparisons to VergeOS should also include how efficiently the infrastructure scales. While raw node count may be critical for some data centers, most organizations seek more efficiency and flexibility in how the VMware alternative scales. Efficient scale means only adding additional nodes after the existing nodes’ resources have been used to their full potential. An efficient infrastructure can deliver more performance from fewer nodes, which lowers both capital and operational costs.
The comparison of efficient scale is where VergeOS has a clear and more practical advantage. We repeatedly have VMware customers moving to our platform and are seeing better performance from their applications even though it runs on the same hardware. The lack of efficiency is why many customers who originally consider HCI end up selecting a classic three-tier architecture. UCI delivers the efficiency they need.
As a result, customers can add even more workloads to the environment without purchasing additional hardware. In some cases, they have been able to delay new server purchases for years, thanks to the implementation of VergeOS. The efficiency results from integrating the networking and storage components and, frankly, just better execution of the code. Our efficiency means that while customers can scale further with VergeOS, they won’t have to scale as often.
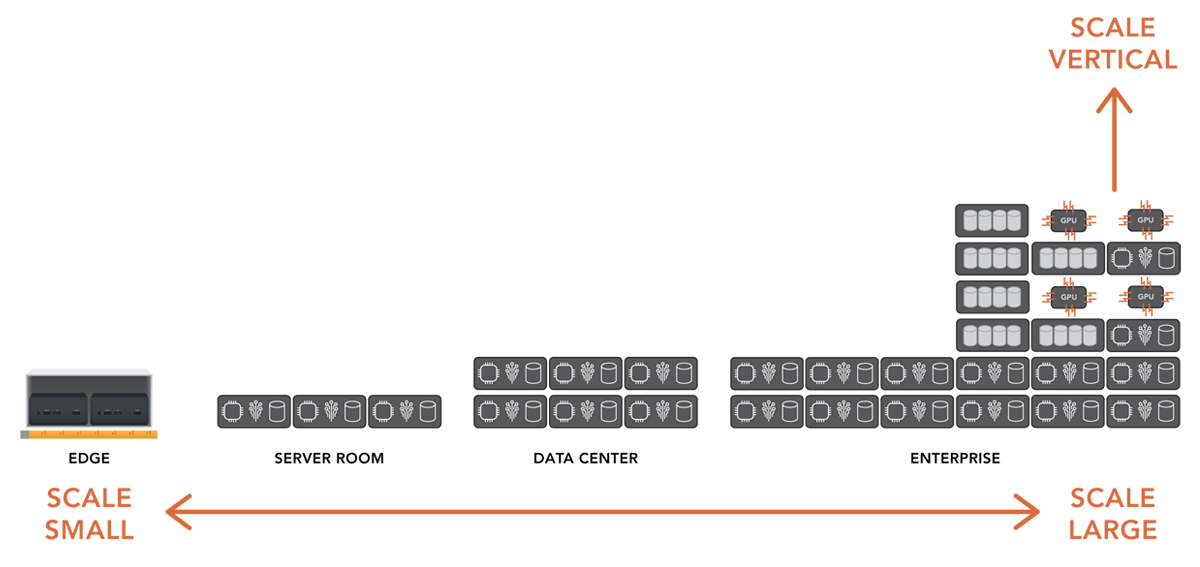
VergeOS’ Flexible Scale is Better Than VMware Scale
VMware scale comparisons to VergeOS must also include how flexible it is to scale the cluster. Most customers will want to start small and add nodes as workloads and organizational growth demand it. Instead, most customers will grow their environment over time. During that time, their needs will change, and so will technology. The first dozen or so nodes they start with may only be available after the time they add their fiftieth node.
With VMware, you must create an entirely separate cluster if you add different servers with different configurations, like an AMD processor instead of an Intel processor. While there is a common management interface, plenty of functions need to be set separately. HCI Storage is a good example. It is locked to the cluster and can’t be shared across clusters.
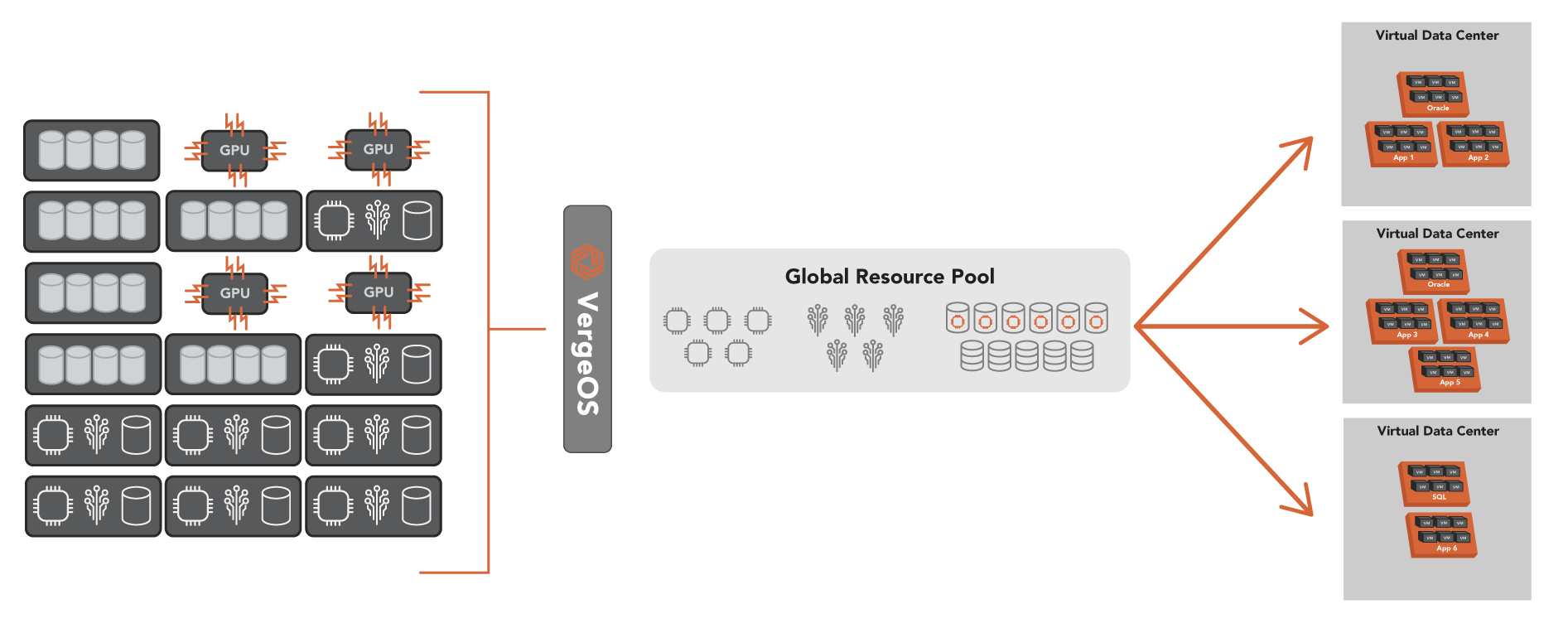
With VergeOS, IT can bring in servers of vastly different configurations, different processors, different storage media types, and even with GPUs. They are all managed by a single VergeOS environment. Resources can be isolated to a single virtual data center or distributed across multiple virtual data centers.
VergeOS’ flexibility means that the software can adapt to the organization’s needs and integrate new hardware innovations. IT can use VergeOS for mainstream applications with modest performance requirements, then add high-performance nodes with GPUs and NVMe flash or high-capacity nodes for file sharing and backup. Each of these different hardware configuration types is still managed within the same VergeOS instance.
Conclusion
VMware scale comparisons to VergeOS will show how superior VergeOS is in all the ways IT measures scalability. It is affordable for small data centers and enables them to deliver more performance on less hardware while also providing robust networking functionality. Enterprises can support various workloads thanks to VergeOS’ ability to mix nodes and use Virtual Data Centers. There is no technical limit on how many nodes, VergeOS supports, but its efficiency means you will require less than VMware.
It is also important to remember that VergeOS is a complete offering and requires no compromises versus VMware. It provides robust data protection, massive capacity scalability, and almost bare-metal performance of virtualized applications. VergeOS’ storage capabilities are so powerful that many customers switch to VergeOS as part of a SAN replacement project.
Understanding VMware DR Components
Understanding VMware DR components allows IT professionals to dramatically reduce spending without compromising recoverability. There are four main components to a VMware disaster recovery (DR) strategy:

- Storage
- Compute
- Network
- Replication Software
The products you select for each of these components impact how much that component will cost and has a ripple effect on the other components in terms of cost and choices. The total of these parts impacts the complexity of your DR strategy and the likelihood of a successful recovery.
To learn more about VMware DR, join us for tomorrow’s Whiteboard Wednesday session, “VMware Disaster and Ransomware Recovery—The Three NEW Best Practices,” at 1:00 PM ET / 10:00 AM PT.
Understanding VMware DR Storage
Understanding VMware DR components requires knowing what type of storage will be in place at the DR site. It represents one of the best opportunities to reduce DR costs. To copy data to the remote DR site, customers often use array-based replication, which typically requires another storage system from the same vendor at the DR site. Customers are forced to pay a premium for a rarely used storage system. Furthermore, since most storage vendors have given up on auto-tiering, the customer cannot use lower-cost hard disk drives at the DR site and then move the workloads to flash storage when a disaster occurs.
Reducing the cost of DR storage requires two capabilities. First, the ability to replicate directly from the VMware environment instead of using the array. Second it must support multiple types of media. Replicating directly from the VMware environment instead of using the array provides a much tighter integration into VMware, enabling a complete copy of data at the DR site. It also enables replicating to a commodity server with drives installed instead of a dedicated storage array. The ability to support multiple types of storage media, flash drives, and hard disk drives, for example, enables IT to take advantage of the fact that hard drive capacity is 8X less expensive than the equivalent flash capacity. The storage system must provide the ability to quickly move the most performance-dependent workloads to a flash tier during disaster recovery testing or an actual disaster.
Understanding VMware DR Compute
Understanding VMware DR components requires knowing the compute requirements at the DR site during a disaster. IT must ensure the DR site can support operations during a disaster. IT no longer has the luxury of ordering hardware on demand because supply chain issues continue to plague the industry. Your DR plan can’t be held up because servers are on backorder for three weeks or more. As a result, the server performance at the DR site must match the server performance at production, at least for the workloads that will be recovered at the DR site.
Reducing the cost of DR Compute requires running more virtual machines on less hardware without impacting performance. VMware is too weighed down by all its add-ons and lack of integration between them. IT needs to eliminate as much of the virtualization tax as possible by using a more efficient hypervisor at the DR site. An alternative VMware hypervisor that is 50% more efficient means a 50% reduction in server costs at the DR site.
Understanding VMware DR Networking
Buying a second set of network hardware for the DR site has the same problem as buying a second storage system; it is expensive. An alternative is to use “dumb switches” and software-defined networking (SDN) capabilities. The issue is the SDN software is often so expensive that its costs all but eliminates the savings of buying “dumb switches.” This high cost is especially true with VMware’s NSX. VMware’s SDN software can add $10,000 or more to the cost of each node in the DR site. Lastly, SDN creates another layer, similar to managing a separate physical network layer. Understanding VMware DR components includes knowing the operational implications of each component selected.
What about Replication Software?
As stated above, many VMware DR strategies depend on array-based replication. While it is sometimes included “free” with the array, it also has the added cost of a second storage system from the same vendor. In most cases, array-based replication is “blind” to the fact that VMware is running on top of it and may not capture all the configuration data. It certainly will not capture all the networking configuration information.
Customers may also use a dedicated replication solution that integrates with VMware. While these solutions capture the VMware environment well, they are costly and don’t help reduce DR storage or network costs.
A Holistic Approach to VMware DR
The fact that there are four components to a VMware DR strategy is the problem. IT must purchase each component and manually stitch them together to work. The coordination between all the components, ensuring all the data and configurations are captured, is critical to the strategy’s success.
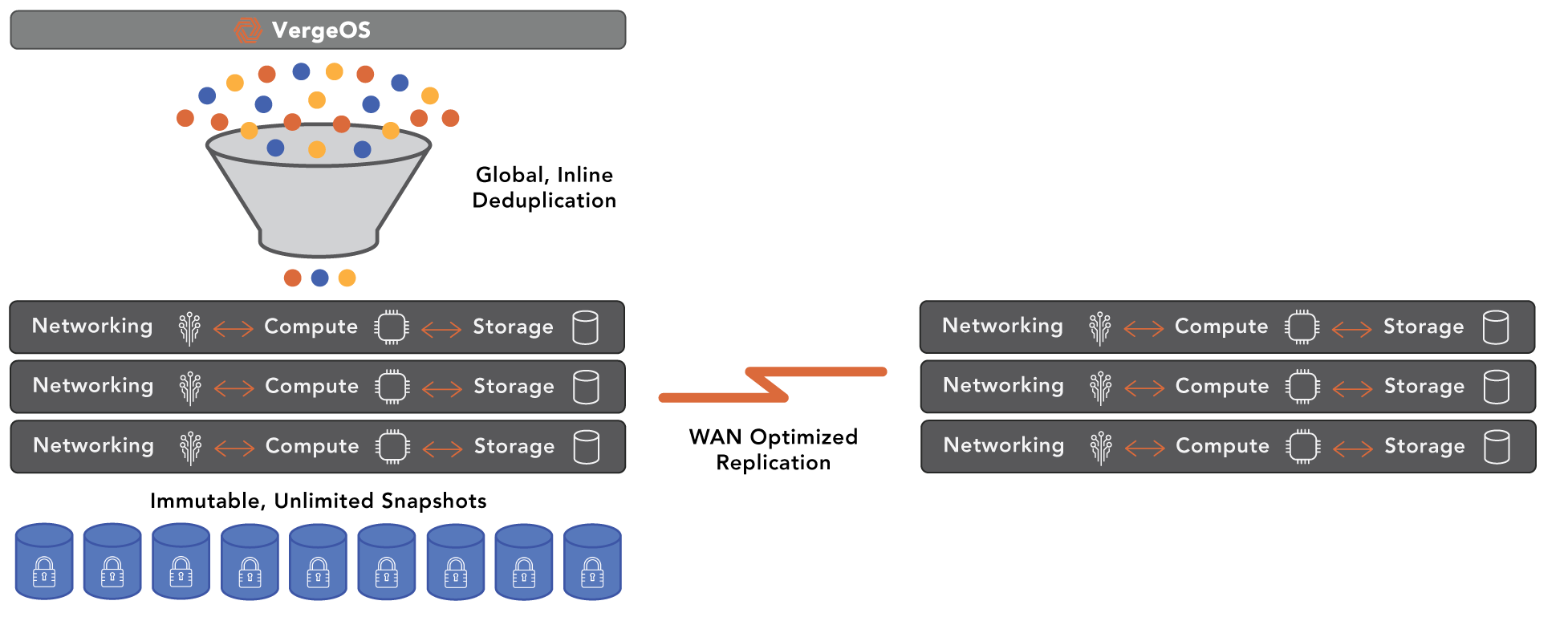
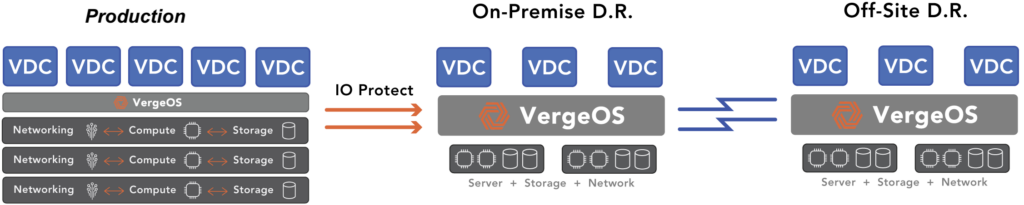
VergeIO’s IOprotect simplifies and reduces VMware DR costs. It makes understanding VMware DR components easy because it reduces the “components” to one. IOprotect is part of VergeOS, an ultraconverged infrastructure (UCI) that integrates networking, compute, storage, and data protection into a single operating environment. It is one piece of software, not four or five.
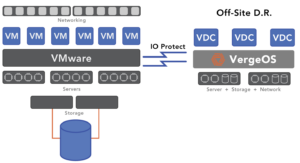
With IOprotect, you can replicate your existing three-tier or hyperconverged infrastructure (HCI) to a single VergeOS environment. It seamlessly connects to your VMware environment and captures all the information you need for a successful disaster recovery strategy. You can also consolidate all your DR computing, storage, and networking requirements into as few as two servers plus a few “dumb switches” at your DR site. If you require more capacity or compute resources, add more nodes, but you won’t need to add many nodes because our customers consistently find they can run more workloads on less hardware. VergeOS is more efficient than VMware. They also require less storage capacity thanks to our high-performance global inline deduplication.
Testing your DR strategy is easy with VergeOS. Our Virtual Data Center (VDC) technology allows you to create a space-efficient, isolated clone of your replicated site. You can test and practice your DR skills while protecting your production VMware environment.
A DR Strategy with a Production Future
IOprotect is just the beginning. Using IOprotect for VMware DR extensively tests all VergeOS capabilities while your VMware environment is under license. You will likely reduce your VMware expenses by more than 60% during that time. Then when it is time to renew VMware in production, and you have to deal with the new, more expensive VMware pricing policies, you have an exit strategy, tested and ready for deployment. Now your cost savings increase even more, as does your operational simplicity.
Preparing VMware for Minor Disasters

IT professionals often plan for major disasters like floods, fires, and hurricanes, impacting their VMware environment, but they also need to spend time preparing VMware for minor disasters. Unlike a major disaster, a minor disaster typically doesn’t require the organization to resume data center operations at a remote disaster recovery (DR) site. Minor disasters include a VMware node failure, storage system failure, a ransomware attack, or an application bug that causes an application outage or data corruption. From the perspective of the IT team, minor disasters are just as painful to work through.
During next week’s Whiteboard Wednesday session, one of our agenda items is preparing for and recovering from minor and major disasters. Our panel of experts will take you through real-world examples of how customers have dealt with these situations.
Users Have No Patience for Minor Disasters
Part of preparing VMware for minor disasters is understanding user expectations. During a major disaster, users tend to be more patient since they can see that the building is underwater, on fire, or shut down for some reason. They also may be dealing with regional issues that are impacting them personally.
During a minor disaster, the IT team does not get the same benefit of user patience. Users are at work or unaware of why they can’t access their data, so they complain quickly and loudly. Even during a ransomware attack, all the lights are on in the data center, so users demand to be up and running. As a result, minor disasters need a particular type of attention. IT needs to restore operations quickly, without much, if any, data loss.
Options for Dealing with Minor VMware Disasters
If a minor disaster occurs, there are typically three available options:
- Fail operations at the DR site and treat the minor disaster like a major disaster. They will then fail that application or data set to the remote site.
- Resolving the disaster using traditional data protection techniques like backup or snapshots.
- Have an on-premises mirror of your entire infrastructure, storage, networking, and compute available for failover.
Treating Minor VMware Disasters as major Disasters
Moving operations to the remote disaster recovery site is the first option when preparing VMware for minor disasters. The remote DR site should have all the components needed to support the application or data set you need to shift to it. IT is treating the minor disaster as if it were major. However, it also creates some additional challenges. First, you must calculate the time it will take to transfer operations and account for any additional outage while the transfer occurs. The chances of data loss are also higher since most organizations don’t update their DR site as frequently as they may protect their primary site.
Second, you must account for enabling your users to connect to the remote site. Unlike a major disaster, some of their applications and data are still available in the core data center. Is the network set up correctly to support this hybrid access?
Third, you need to account for transferring back to the primary site once the problem has been resolved. It will take at least the same time to move an application back into production as it did to move it out. For the most part, this shift was unnecessary since the primary data center was still operational. The data center didn’t have the resources and planning to rapidly recover through a minor VMware disaster.
Treating Minor VMware Disasters as Backup Events
The next option for preparing VMware for minor disasters is to treat it as something the backup process can work through. While all organizations should do backups as frequently as possible, the reality is that organizations only perform backups once daily. The lack of frequency often stems from backup software or hardware limitations. Some organizations may perform two or three backups daily, but there are usually hours of gaps between protection events. Even backups every three to four hours will result in too much data loss for a minor VMware disaster.
Some organizations will supplement the backup process with storage system snapshots. These snapshots enable more granular data protection. Still, most organizations don’t execute snapshots frequently enough to provide any real value in recovery for fear of the performance impact of retaining more than a dozen snapshots. Moreover, with a deep catalog of snapshots, customers frequently have problems finding a suitable snapshot for recovery.
The issue with using the backup process to prepare VMware for minor disasters is the time it takes to recover the data and the amount of data likely to be lost. Even so-called “instant-recovery” options available from some backup software vendors take more than 30 minutes to execute and, because of backup infrequency, result in hours of data loss. Also, if the minor disaster is a storage system failure, all the snapshots are lost, and there is no destination for backup recovery.
Treating minor Disaster as an HA Problem
Many data centers have a small group of applications designated as mission-critical. These applications will often have a mirrored set of resources to ensure high availability (HA) and complete invulnerability to a minor disaster. The difficulty of using HA when preparing VMware for a minor disaster is its extremely high cost, which makes it almost impossible to include a broad section of the organization’s data and applications. Not only does IT have to double the server, network, and storage hardware investment, but it also has to pay for additional software licenses like VMware or storage software. Most organizations provide no discount for the secondary installation, even though it will sit idle most of the time.
The real-time protection of most HA solutions leaves the protected copy vulnerable to the same failure, like a ransomware attack. In addition, the HA solution typically doesn’t translate into a viable off-site solution for major disasters. The result is extra cost and operations effort.
Another Option: Solving the VMware Minor Disaster Problem with IOprotect
VergeIO’s IOprotect capability provides much of the functionality of the HA option at a price lower than the backup option. It can also be the foundation of your remote DR site, consolidating all disaster recovery within a single piece of software. With IOprotect, preparing for and recovering from major and minor disasters is much more straightforward and cost-effective.
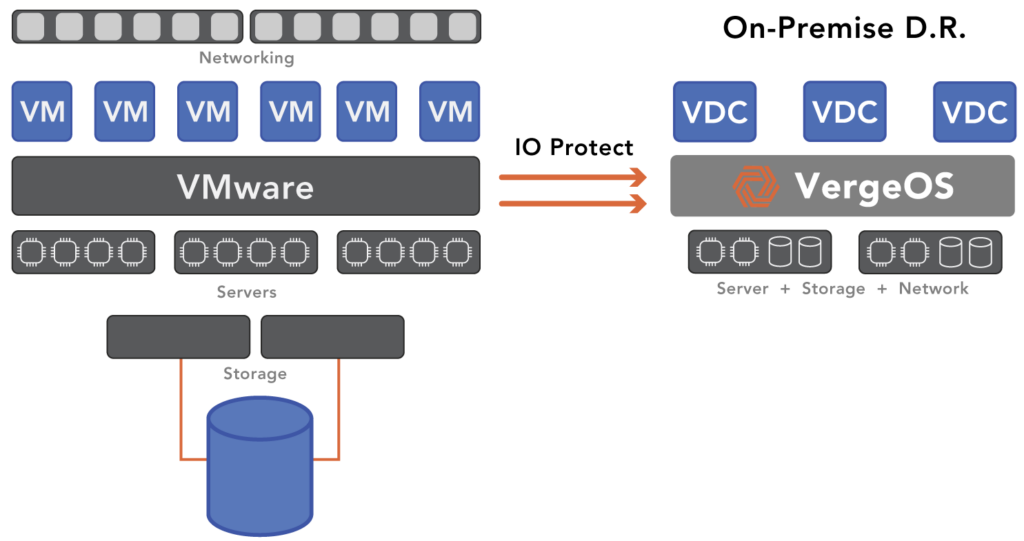
Since IOprotect is built-in to VergeOS, it gains the same software efficiencies, which means it can run more workloads on less hardware. That means your secondary minor can run on fewer nodes and use commodity storage internal to the server, avoiding the cost of a second SAN. Many customers use older-generation servers, enabling them to establish a standby environment for a fraction of the production price. IOprotect is priced for the use case and is up to 80% less expensive than VMware.
Once the minor disaster recovery environment is established, customers can use IOprotect to replicate an instance to the DR site, which also benefits from the same efficiency and lowers the cost of preparing for a major disaster. Organizations can use IOprotect just for protection from major disasters, but its cost-effectiveness makes protecting against minor disasters simple and affordable. It executes near-realtime data protection, making immutable, space-efficient snapshot copies of production data locally and then replicating it to a remote DR site.
No matter the failure, VergeOS with IOprotect enables rapid recovery. It is a complete disaster recovery solution, not just storage. All capabilities, storage, networking, and computing are available on the second minor and third remote DR instances. It also lays the groundwork for a VMware Exit if you decide to reduce costs further and increase the capabilities of the production environment. With VergeOS, you can lower your infrastructure costs by more than 70% and extend its life by years.
Comparing VMware to VergeOS
Most of the questions in a recent event we did with Truth In IT were about comparing VMware to VergeOS. There were so many we couldn’t answer them all during the session. Since we think these are questions that even IT professionals who didn’t attend the event will ask, we’ve assembled a blog answering them. If you missed the event, you can watch the on-demand version here.
In addition to comparing VMware to VergeOS questions, there were plenty of questions related to resiliency, ransomware protection, and scalability. We will get to all those questions in a future blog.
The top comparing VMware to VergeOS questions were:
- Is VergeOS a complete replacement for VMware?
- How do you migrate from VMware to VergeOS?
- Is using VergeOS easier than using VMware?
- Is VergeOS better for smaller organizations than VMware?
- Is VergeOS suitable for large data centers?
- How does VergeOS’ performance compare to VMware’s?
- How does VergeIO’s support compare to VMware’s?
Before we answer the questions, let’s see how VergeOS compares to VMware.
Comparing VMware to VergeOS as a Data Center Platform
About five years ago, VMware’s VMworld event theme was “Software Defined Data Center. (SDDC)” The company wanted to move beyond software-defining a server with their hypervisor toward software-defining storage (vSAN) and the network (NSX). Organizations that embrace an SDDC concept can use whatever hardware they wish to meet their needs. If they become dissatisfied with a software vendor, like VMware, they can switch without being forced to replace hardware. The customer is in control.
At VergeIO, we agree with the premise of SDDC but disagree with VMware’s execution. Instead of creating a tightly integrated data center operating system, they, through acquisition, created a stack of software packages that IT must manage separately. They were building a hyperconverged infrastructure (HCI). The problem with HCI is that while the architecture bundles the data center’s three primary components (compute, network, storage), they, are still three separate entities. Where the old three-tier stack (Network-Hypervisor-SAN) was physically separated, HCI is logically separated. This physical or logical separation leads to continued complexity and lack of efficiency. It doesn’t solve anything.
VergeOS integrates into a single code base, networking, server virtualization, and storage. We call it Ultraconverged Infrastructure (UCI). One data center operating system is easier to manage and is far more efficient than one that operates as a series of interconnected parts. As a result, customers get better performance and scalability from the existing hardware.
Comparing VMware to VergeOS highlights the core difference is how the development teams craft their solutions. Do you stack a bunch of separate software packages together and try to hide their separation through a common interface, or do you provide all the functionality through a single interface? One leads to inefficient use of hardware and expensive, complicated licensing agreements. The other leads to very efficient hardware use and a simple, inexpensive licensing model.
To learn more about the VergeOS architecture, watch this deep-dive LightBoard video of with CTO and founder, Greg Campbell.
Is VergeOS a Complete Replacement for VMware?
Yes, but you don’t have to flip the switch on day one and throw out VMware. Most customers move to VergeOS gradually. They start with a proof of concept, which is usually up and running in less than an hour, then move to use our IOprotect solution to reduce their disaster recovery costs. After that, VergeOS now has a copy of all the data, so they may start using VergeOS for test-dev, QA, or reporting. Next, they may start putting new workloads into the environment and then finally start moving production workloads. The result is a seamless transition that goes at a pace you define.
If you want to learn how to enhance your VMware DR strategy while lowering costs, register for our interactive virtual whiteboard session, live on April 12th.
How do You Migrate from VMware to VergeOS
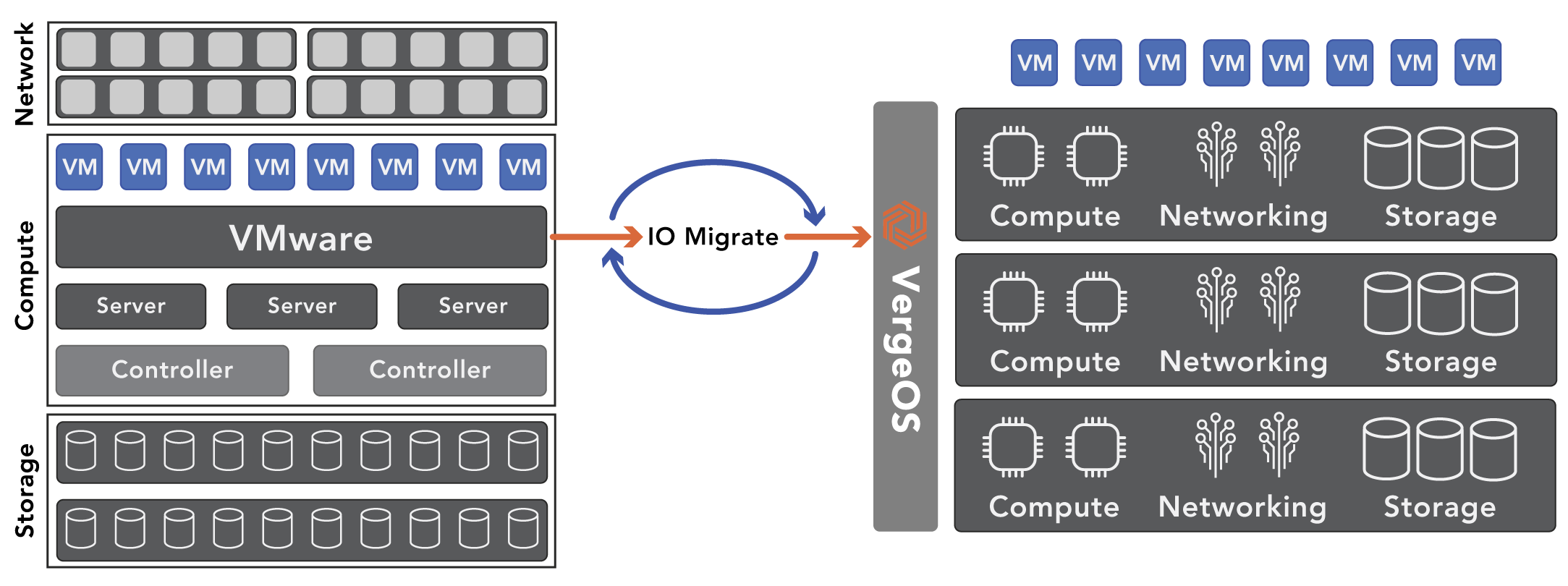
Comparing VMware to VergeOS requires migration, and our IOmigrate capability makes that seamless. Once you install VergeOS on a couple of nodes, you can point it at the VMware cluster, and you’ll see all the virtual machines (VM) in our interface. At that point, you can select some or all of the virtual machines and import them into the VergeOS environment. Once the VMs are running under VergeOS, take a snapshot of them, which protects the original copy, then you can stress-test it to your heart’s content without fear of data loss. Our snapshots are space efficient, immutable, and don’t impact performance, so you can take as many as you want and retain them indefinitely.
Sign up for our Digital Learning Guide and learn how to create a VMware Exit Strategy.
Comparing VMware to VergeOS Ease of Use
It is easy for any vendor to claim that their solution is easier to use than another solution. To compare VMware to VergeOS regarding ease of use, I’ll relay what our customers tell us. Most tell us they can get the proof of concept going in an hour. The move to using us as a DR target and the move to production is seamless because it is all the same software.
Operationally the common theme is “it just works” and “I go for weeks without even touching it.” They all rave about the ease of implementing patches and software updates. That is the value of one software to drive the entire data center. The user interface is very easy to interact with while still enabling very advanced capabilities.
Is VergeOS Suitable for Small Organizations
Small Organizations, or what we call the server room use case, embrace the idea of VergeOS for several reasons. First, you can easily start with two nodes, loaded with storage, and, in many cases, address all your needs for virtualization, storage, and networking. Small data centers or server rooms often also mean small IT teams. One data center operating system that controls all functions makes day-to-day operations easy. VergeOS is also inexpensive. We don’t charge by cores, memory, or even storage capacity. The software is priced per node, so two or three licenses are all you need for a typical server room deployment.
Is VergeOS Suitable for Large Data Centers
VergeOS’ suitability for small organizations doesn’t mean it isn’t suitable for large organizations. We have customers with over one hundred nodes in a single instance of VergeOS. Those customers typically manage thousands of virtual machines and multiple petabytes of capacity. They also enjoy and benefit from the ease of use and cost savings of VergeOS.
Comparing VMware to VergeOS Performance
The efficiency of VergeOS helps both large and small data center customers. We are often installed on the same hardware that used to run VMware. Customers find the VergeOS environment performs much better than VMware. The improvement in performance means they can virtualize more workloads on fewer servers, delay the planned purchase of new servers, and run servers for years longer than expected. They can also virtualize some workloads that they thought must run on bare metal.
Comparing VMware to VergeOS Support
It is hard to compare support between the two companies. We hear from customers switching to VergeOS that the quality of VMware support is declining, especially for smaller customers. I speak to customers every week who are astounded by the quality of our technical support and amazed at how far the team will go to help them fix problems that don’t have anything to do with VergeOS.
Conclusion
Comparing VMware to VergeOS shines a light on the efficiency of our software. Our developers continue to invest in ensuring the software runs at its most optimal level, gets the most out of the available hardware resources, and presents its power in the simplest form possible. The result is a drastic reduction in infrastructure costs and dramatic increases in operational efficiency. This craftsmanship is immediately apparent when you install the software and is why so many customers are switching from VMware and Hyper-V to VergeOS.
Next Steps
Try It: Register to download an evaluation copy of the software.
Watch: A LightBoard Video of our CTO discussing the VergeOS architecture.
Learn: How to Create a VMware Exit Strategy with our Digital Learning Guide
Register: For our next Whiteboard Wednesday, VMware Disaster and Ransomware Recovery—The Three NEW Best Practices
VergeIO Slashes Cost of VMware Disaster Recovery
Ann Arbor, Mich, March 28th, 2023 — VergeIO, the Ultraconverged Infrastructure (UCI) company, today announced that it is providing a robust disaster recovery solution, IOprotect, for VMware. The solution promises to reduce customer costs by more than 60% and, in most cases, requires no additional hardware while improving recoverability and resiliency.
IOprotect is part of VergeIO’s Ultraconverged Infrastructure (UCI) solution VergeOS and enables customers to take a safe first step of a VMware Exit Strategy. Customers can load IOprotect on the existing hardware at their disaster recovery location and replicate, in near real-time, their VMware virtual machines to it. IOprotect enables customers to cut costs almost immediately while increasing the number of workloads protected thanks to the efficiency of VergeOS.
“Disaster Recovery is an excellent first step in a VMware Exit strategy. It enables customers to fully vet the potential alternative by having it run a function that is critical and vital to the enterprise,” said Yan Ness, VergeIO CEO, “Later, once customers experience the stability and robust capabilities of VergeOS, they seamlessly upgrade to the full version of VergeOS. Then they are ready to transition their production environment as their VMware licensing agreements expire, face a VMware audit, or want to avoid another round of disruptive upgrades.”
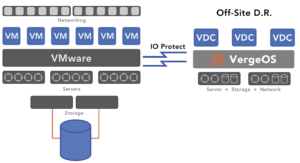
The IOprotect solution enables customers to maintain continuously updated copies of their VMware virtual machines on VergeOS but does not replace backup solutions. Instead, it is a radically affordable DR alternative to software from VMware, Zerto, array-based replication Disaster Recovery as a Service (DRaaS) bundles. It is also significantly easier to set up, operate and maintain.
IOprotect runs on the customer’s hardware at a site they deem appropriate for disaster recovery, eliminating the shock of unexpectedly high monthly bills from public cloud providers. With IOprotect, customers can restart protected workloads within minutes of a site outage. If organizations don’t have a suitable DR site, they can connect with one of VergeIO’s IOpartners and easily address their disaster recovery needs with a few mouse clicks.
Due to the solution’s cost-effectiveness and modest hardware requirements, many customers leverage existing hardware to create an on-premises DR instance for disasters that are not site-wide. This “on-site” DR environment protects them from local failures like storage system failure, double drive failures, and ransomware corruption. The VergeOS environment maintains immutable copies of the customer’s VMware virtual machines, which increases their resiliency to a ransomware attack.
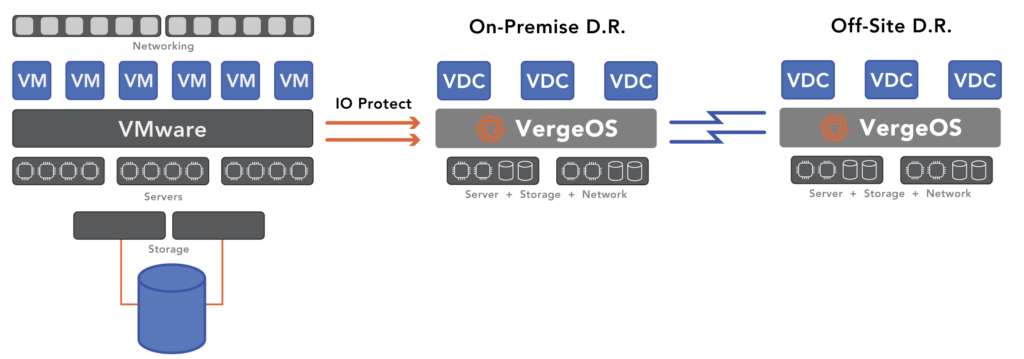
Disasters and ransomware attacks are something to prepare for but not something customers must deal with daily. It doesn’t make sense to pay full price for a solution that sits waiting for use. IOprotect low price enables customers to reduce DR costs and begin investigating a possible VMware Exit strategy. IOprotect is licensed per target node, not capacity. It can start with as few as two nodes and support unlimited virtual machine sources. Customers can run workloads for 36 hours to validate disaster recovery readiness.
Customers can easily upgrade the solution for other use cases like workload spike mitigation, testing, development, reporting, and eventually complete VMware migration.
To learn more, join VergeIO on Wednesday, April 12th at 12:30 pm ET, for “ VMware Disaster and Ransomware Disaster Recovery, The Three New Best Practices,” for an interactive whiteboard session describing the three new best practices for rapidly recovering from these worse case scenarios.
About VergeIO
VergeIO is the Ultraconverged Infrastructure (UCI) company. Unlike hyperconverged infrastructure (HCI), it rotates the traditional IT stack (compute, storage, and networking) into an integrated data center operating system, VergeOS. Its efficiency enables greater workload density on the same hardware with high levels of data resiliency. The result is dramatically lower costs and greatly simplified IT.