While hyperconverged infrastructure (HCI) catches the attention of many IT professionals, the HCI Disaster Recovery problem, while seldom talked about, could be its greatest weakness. Proper HCI protection and disaster recovery typically require a separate infrastructure with its own software and hardware. This requirement complicates a critical process, creating a high risk of failure while dramatically increasing costs.
What is the HCI Disaster Recovery Problem
Part of the HCI Disaster Recovery problem is that most data protection solutions have to protect HCI architectures as traditional three-tier architectures. They back up through the hypervisor and to a separate storage system. That separate storage system is often scale-out in nature, so you have nodes backing up nodes.
Disaster recovery requires the same HCI configuration in the remote site as in the primary site. Also, the deduplication capabilities that most HCI vendors provide are bolt-on, which they deliver years after the HCI software first comes to market. As a result, it can’t deduplicate across HCI clusters. If the organization has multiple HCI clusters in one or more locations, it must transmit all the data to the disaster recovery site.
The HCI Disaster Recovery Problem Triples Inefficiency
HCI is incredibly inefficient. The inefficiency is the result of forcing customers to expand with like nodes. If all you need is more processing power, you can’t easily add more advanced CPUs or GPUs to the existing cluster. Even if you use the same processor type, you can’t buy nodes that are primarily processors; you must buy additional storage to match the other nodes in the cluster.
Backing up an HCI architecture, because conventional wisdom is to back up to a scale-out storage system, means you are doubling the inefficiency of the infrastructure. That scale-out backup storage suffers from the same inefficiency as scale-out HCI except in reverse. With scale-out backup storage, you are dragging along, and paying for, more processing power than you probably need just to get capacity.
Making sure an HCI architecture is protected from disaster triples its inefficiency. Forcing identical nodes in the disaster recovery site means that the HCI solution duplicates the same inefficiency at the disaster recovery site as in the primary location. Suppose you are replicating the backup infrastructure in addition to the HCI infrastructure because you don’t trust HCI replication. In that case, you are quadrupling the cost of data protection and disaster recovery costs.
The HCI Ransomware Recovery Problem
Ransomware is another form of disaster. It is unique in that the data center is still operational, but users and applications are not. HCI also has a ransomware recovery problem. HCI solutions do not harden their software. Since most are mostly Software Defined Storage (SDS) solutions that claim to be HCI, they run as a virtual machine (VM) within a hypervisor like VMware or Hyper-V. They are at the mercy of that hypervisor’s ransomware hardening.
Running storage as a VM castrates a vital line of ransomware defense, snapshots. Recovering quickly from a ransomware attack requires frequent, immutable snapshots. Given the latest ransomware attack profiles, IT must retain these snapshots for months. Storage running as a VM suffers from the same virtualization tax as other VMs. As a result, they can only keep a few snapshots before needing to expel them for performance reasons.
Solving the HCI Disaster Recovery Problem
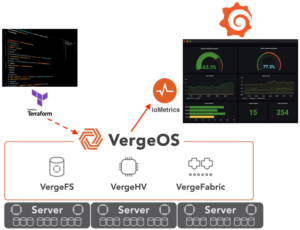
Solving the HCI disaster recovery problem requires rethinking HCI. First, the IT stack (compute, storage, networking) needs to be integrated, not layers. At VergeIO, we call this rotating the stack, which removes the layers and creates a cohesive data center operating system (DCOS), VergeOS. It is a single piece of software, not dozens. We call it Ultraconverged Infrastructure. Next week we’ll be hosting a live webinar that compares HCI to UCI. Register here.
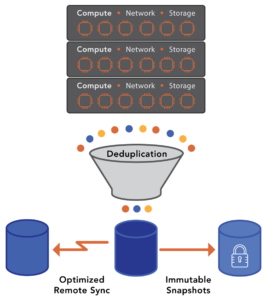
While we support external backup applications, VergeOS includes built-in data protection and replication capabilities. They, like everything else, are integrated into the core code, so they operate with minimal overhead. You can execute immutable snapshots frequently and retain those snapshots indefinitely without impacting performance.
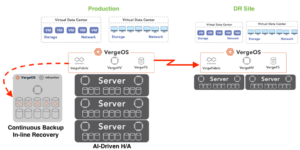
VergeOS also supports different node types, so the disaster recovery site can use different hardware than the primary. Also, VergeOS supports global, inline deduplication so that if you are replicating from multiple sites to a central disaster recovery location, it only replicates the unique data from each site. With VergeOS, transfers are fast, and disaster recovery storage costs are negligible.
The HCI Disaster Recovery Problem Creates Compromise
Because of cost and complexity, many organizations compromise when establishing their disaster recovery site. The enforcement of like hardware doubles server acquisition costs, and the lack of efficient data storage can triple or more storage costs.
The most common compromise is using the backup infrastructure as the disaster recovery solution. Backup software can replicate and even deduplicate data, but when it stores that data on the remote site, it is in the backup software’s format. It isn’t operational. If there is a disaster, the organization must wait, potentially days or hours, for restore job completion before allowing access.
Using backup as the disaster recovery solution also makes testing and practicing the recovery process much more complicated and time-consuming. The result is less frequent testing and no practice. The reason most disaster recoveries fail is a lack of testing and experience.
Eliminating Disaster Recovery Compromise
VergeOS provides no-compromise disaster recovery. The costs at the disaster recovery site are easily controlled thanks to node flexibility and data deduplication. The data at the DR site is live and ready to instantiate at a moment’s notice.
Networking is also a source of disaster recovery failures. Misconfigurations, improper remapping, and incompatible hardware between locations can cause many problems. VergeOS integrates software-defined networking and alleviates these problems, ensuring that newly recovered data centers are easily accessible by users and applications.
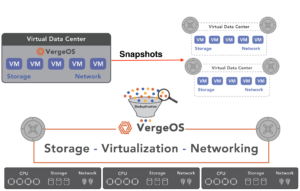
Testing, thanks to our snapshot functionality, is also easy. Thanks to our Virtual Data Center (VDC) technology, a snapshot of an entire data center can be made in seconds. That snapshot can then be mounted for recovery testing purposes. Deduplication ensures that the only growth in capacity is changes made to the disaster recovery dataset while the test is executing.
Data protection and disaster recovery have been problematic since the dawn of the data center. Continuing to try the same old thing (replace backup software, replace backup storage, try to find a better replication solution, pray the network works) isn’t the answer. With VergeOS, we start at the source of the problem the production infrastructure itself.
Learn More:
- Register for our live webinar, “Beyond HCI — The Next Step in Data Center Infrastructure Evolution.” During the webinar, VergeIO’s Principal Systems Engineer, Aaron Reed, and I will compare HCI and UCI in-depth. I’m even going to talk Aaron into giving you a live demonstration of the solution of VergeOS in action.
- Subscribe to our Digital Learning Guide, “Does HCI Really Deliver?”
- Sign-up for a Test Drive – Try it yourself, and run our software in your labs.