Why Your Infrastructure Must Be More Reliable Than a Laptop
Virtual Desktop Infrastructure (VDI) promises centralized management, enhanced security, and simplified desktop provisioning, but ensuring VDI resilience ultimately determines its success. Users expect their virtual desktops to be available whenever needed, and IT administrators can’t afford downtime. The last thing an IT team wants to hear is that a user’s personal laptop is more reliable than the VDI environment!
📺 Want to see how a resilient VDI infrastructure works in the real world? Watch our on-demand webinar featuring VergeIO, Inuvika, and Kelley Allen from CCSI demonstrating the solution in his production environment.
Register here.
To prevent this, organizations must deploy a highly resilient VDI architecture that can withstand hardware failures, ensure uninterrupted access, and protect against data loss. While solving performance issues like boot storms is essential, its potential performance doesn’t matter if the infrastructure is down. Ensuring VDI Resilience means choosing an infrastructure that can handle node failures, multiple simultaneous drive failures, and even full-site disruptions without impacting end-user availability.
The Cost of Downtime in VDI
When a user’s local laptop fails, one user is down. However, if a VDI system fails, hundreds or thousands of users can be left without access to their desktops and applications, bringing productivity to a standstill.
Downtime in a VDI environment results in:
- Lost productivity – Employees, students, or healthcare professionals can’t access their critical applications.
- IT scrambling to recover – Administrators are forced into emergency troubleshooting and system restores.
- Potential data loss – Critical work may be lost if desktops or application servers aren’t adequately protected.
- User frustration and resistance – If VDI is unreliable, users may abandon it in favor of personal devices, undermining IT security and control.
To prevent these issues, a truly resilient VDI platform must deliver continuous availability and data protection.
The Challenges Ensuring VDI Resilience
Traditional virtualization platforms often rely on RAID-based storage protection and compute clustering to maintain uptime. While these methods provide some level of redundancy, they have critical weaknesses:
- RAID can’t handle multiple simultaneous drive failures – If two or more drives fail simultaneously in a RAID 5 or RAID 6 array, data loss occurs, leading to a time-consuming and costly recovery process.
- Compute clustering requires rebalancing workloads – In a node failure, traditional clusters must migrate VDI sessions to remaining nodes, often causing performance degradation or session disconnects.
- Long rebuild times and performance loss – If a RAID array or vSAN-based storage system loses a drive, the rebuild process can take hours or even days, significantly slowing performance during that time.
For a VDI environment to be considered truly resilient, it must go beyond these traditional methods and offer:
- Self-healing storage that can survive multiple drive failures.
- Multi-node redundancy that intelligently shifts workloads without performance loss.
- Built-in high availability that prevents downtime without complex manual intervention.
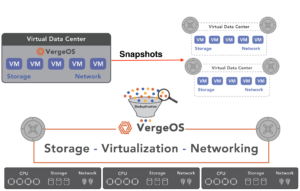
Ensuring VDI Resilience with a Distributed, Resilient Architecture
A highly resilient VDI infrastructure must eliminate single points of failure and distribute resources across nodes to ensure seamless operation even during hardware failures.
A next-generation VDI platform should incorporate:
- Distributed storage mirroring: Instead of relying on RAID, data should be mirrored across multiple nodes, allowing desktops and applications to remain accessible without the prolonged performance impact of a RAID rebuild.
- Automated failover: If a compute node fails, virtual desktops should intelligently shift to another node, which is most qualified to host them, without user disruption or IT intervention.
- Per-VM and per-disk fault tolerance: Protecting individual VDI sessions and applications at a granular level ensures that even partial infrastructure failures don’t impact the entire environment.
- Self-healing capabilities: The system should automatically rebalance data and workloads in the background, reducing IT workload and recovery times.
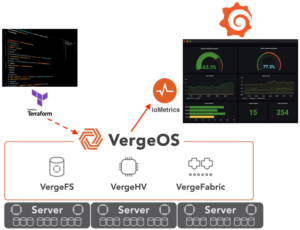
VergeOS: Ensuring VDI Resilience Without Complexity
VergeOS is designed to deliver a highly resilient VDI infrastructure by integrating virtualization, storage, and networking into a single, fault-tolerant platform. Unlike traditional virtualization platforms that rely on RAID-based storage or software-defined storage layers that introduce bottlenecks, VergeOS provides:
- Multi-node fault tolerance: If a node fails, workloads are intelligently transferred to another node without performance degradation.
- Distributed mirroring instead of RAID: Data is mirrored across multiple storage devices, ensuring production performance without RAID-rebuild overhead.
- Cluster Hot Spare: VergeOS’ ioGuardian protects from multiple simultaneous drive or server failures, providing data to impacted virtual desktops inline without interruption.
- No dependency on external storage: Traditional SAN or NAS solutions introduce single points of failure. VergeOS eliminates this risk by making storage an integrated, distributed component of the virtualization platform while providing superior performance.
- Automatic recovery and rebalancing: The system self-heals by redistributing workloads, reducing administrative overhead.
With VergeOS, IT teams can ensure that VDI infrastructure is always more reliable than a user’s laptop, providing uninterrupted access even in the face of hardware failures.
Ensuring VDI Resilience from Data Center Disaster
Beyond local resilience, organizations must also prepare for full-site outages caused by natural disasters, power failures, or regional disruptions. A robust VDI strategy includes protecting users from node and drive failures and ensuring that the entire desktop environment can fail over to a secondary location with minimal disruption.
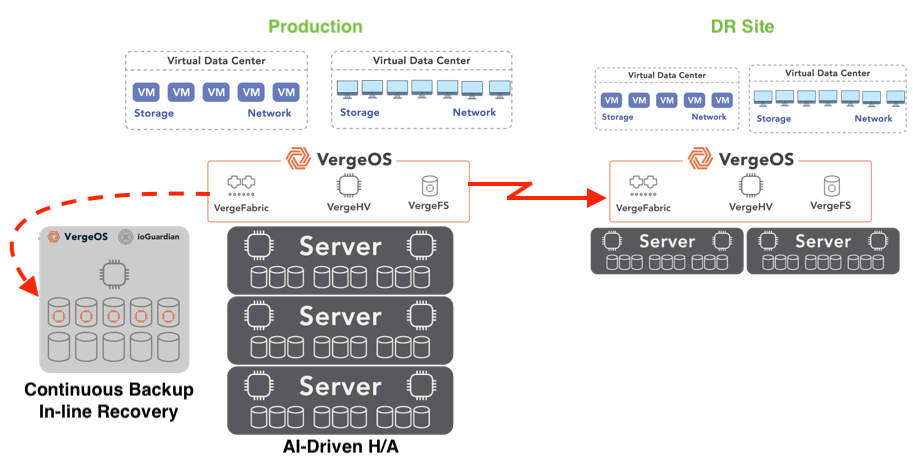
VergeOS addresses this challenge by integrating VergeFabric, a built-in software-defined networking layer that supports advanced routing protocols such as BGP (Border Gateway Protocol). When combined with VergeOS’s native replication capabilities, this allows organizations to replicate virtual desktops and application workloads between primary and secondary sites securely and efficiently. Routing can automatically shift users to the secondary location in a disaster without requiring manual reconfiguration.
This level of integration ensures that VDI environments are protected at the hardware and cluster level and resilient across geographic regions. Users can continue accessing their virtual desktops from anywhere, even if the primary site becomes unavailable—delivering true business continuity for the virtual desktop infrastructure.
📺 Learn More About Ensuring VDI Resilience.
Watch our detailed on-demand webinar with VergeIO, Inuvika, and Kelley Allen from CCSI demonstrating their resilient VDI solution.
Register here.
Conclusion
VDI success depends on reliability. Organizations investing in virtual desktops must ensure their infrastructure is built for resilience, not just performance. Traditional RAID-based storage and clustered compute architectures introduce points of failure that can disrupt users and drive up IT support costs.
A resilient VDI platform must:
- Protect against node and drive failures without downtime.
- Eliminate RAID limitations with a more flexible, distributed storage approach.
- Automate recovery and rebalancing to minimize IT intervention.
- Ensure uninterrupted user access, no matter what happens at the hardware level.
By choosing an integrated, efficient, fault-tolerant architecture, IT leaders can provide a seamless, always-on VDI experience that outperforms the reliability of any physical laptop or desktop.