IT professionals often plan for major disasters like floods, fires, and hurricanes, impacting their VMware environment, but they also need to spend time preparing VMware for minor disasters. Unlike a major disaster, a minor disaster typically doesn’t require the organization to resume data center operations at a remote disaster recovery (DR) site. Minor disasters include a VMware node failure, storage system failure, a ransomware attack, or an application bug that causes an application outage or data corruption. From the perspective of the IT team, minor disasters are just as painful to work through.
During next week’s Whiteboard Wednesday session, one of our agenda items is preparing for and recovering from minor and major disasters. Our panel of experts will take you through real-world examples of how customers have dealt with these situations.
Users Have No Patience for Minor Disasters
Part of preparing VMware for minor disasters is understanding user expectations. During a major disaster, users tend to be more patient since they can see that the building is underwater, on fire, or shut down for some reason. They also may be dealing with regional issues that are impacting them personally.
During a minor disaster, the IT team does not get the same benefit of user patience. Users are at work or unaware of why they can’t access their data, so they complain quickly and loudly. Even during a ransomware attack, all the lights are on in the data center, so users demand to be up and running. As a result, minor disasters need a particular type of attention. IT needs to restore operations quickly, without much, if any, data loss.
Options for Dealing with Minor VMware Disasters
If a minor disaster occurs, there are typically three available options:
- Fail operations at the DR site and treat the minor disaster like a major disaster. They will then fail that application or data set to the remote site.
- Resolving the disaster using traditional data protection techniques like backup or snapshots.
- Have an on-premises mirror of your entire infrastructure, storage, networking, and compute available for failover.
Treating Minor VMware Disasters as major Disasters
Moving operations to the remote disaster recovery site is the first option when preparing VMware for minor disasters. The remote DR site should have all the components needed to support the application or data set you need to shift to it. IT is treating the minor disaster as if it were major. However, it also creates some additional challenges. First, you must calculate the time it will take to transfer operations and account for any additional outage while the transfer occurs. The chances of data loss are also higher since most organizations don’t update their DR site as frequently as they may protect their primary site.
Second, you must account for enabling your users to connect to the remote site. Unlike a major disaster, some of their applications and data are still available in the core data center. Is the network set up correctly to support this hybrid access?
Third, you need to account for transferring back to the primary site once the problem has been resolved. It will take at least the same time to move an application back into production as it did to move it out. For the most part, this shift was unnecessary since the primary data center was still operational. The data center didn’t have the resources and planning to rapidly recover through a minor VMware disaster.
Treating Minor VMware Disasters as Backup Events
The next option for preparing VMware for minor disasters is to treat it as something the backup process can work through. While all organizations should do backups as frequently as possible, the reality is that organizations only perform backups once daily. The lack of frequency often stems from backup software or hardware limitations. Some organizations may perform two or three backups daily, but there are usually hours of gaps between protection events. Even backups every three to four hours will result in too much data loss for a minor VMware disaster.
Some organizations will supplement the backup process with storage system snapshots. These snapshots enable more granular data protection. Still, most organizations don’t execute snapshots frequently enough to provide any real value in recovery for fear of the performance impact of retaining more than a dozen snapshots. Moreover, with a deep catalog of snapshots, customers frequently have problems finding a suitable snapshot for recovery.
The issue with using the backup process to prepare VMware for minor disasters is the time it takes to recover the data and the amount of data likely to be lost. Even so-called “instant-recovery” options available from some backup software vendors take more than 30 minutes to execute and, because of backup infrequency, result in hours of data loss. Also, if the minor disaster is a storage system failure, all the snapshots are lost, and there is no destination for backup recovery.
Treating minor Disaster as an HA Problem
Many data centers have a small group of applications designated as mission-critical. These applications will often have a mirrored set of resources to ensure high availability (HA) and complete invulnerability to a minor disaster. The difficulty of using HA when preparing VMware for a minor disaster is its extremely high cost, which makes it almost impossible to include a broad section of the organization’s data and applications. Not only does IT have to double the server, network, and storage hardware investment, but it also has to pay for additional software licenses like VMware or storage software. Most organizations provide no discount for the secondary installation, even though it will sit idle most of the time.
The real-time protection of most HA solutions leaves the protected copy vulnerable to the same failure, like a ransomware attack. In addition, the HA solution typically doesn’t translate into a viable off-site solution for major disasters. The result is extra cost and operations effort.
Another Option: Solving the VMware Minor Disaster Problem with IOprotect
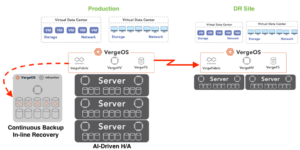
VergeIO’s IOprotect capability provides much of the functionality of the HA option at a price lower than the backup option. It can also be the foundation of your remote DR site, consolidating all disaster recovery within a single piece of software. With IOprotect, preparing for and recovering from major and minor disasters is much more straightforward and cost-effective.
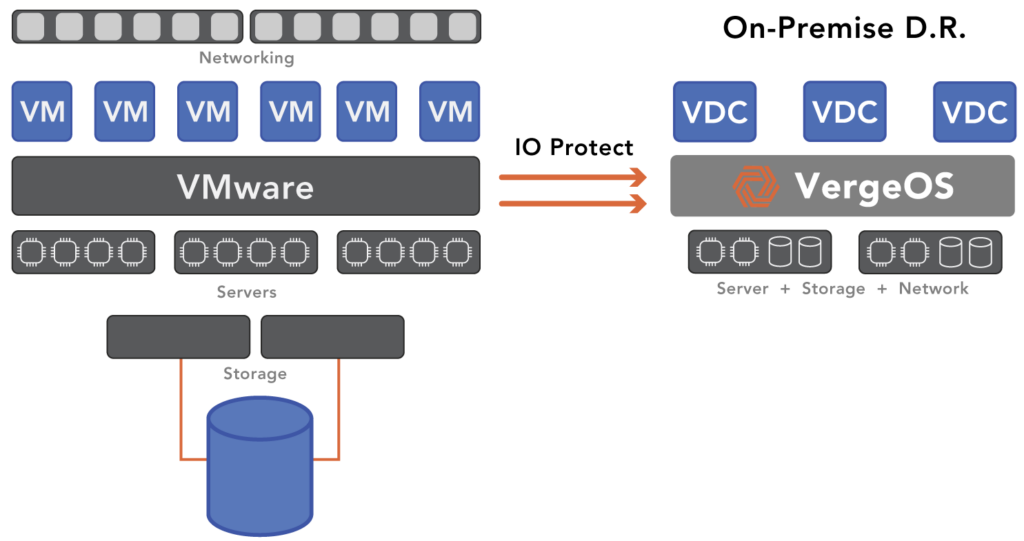
Since IOprotect is built-in to VergeOS, it gains the same software efficiencies, which means it can run more workloads on less hardware. That means your secondary minor can run on fewer nodes and use commodity storage internal to the server, avoiding the cost of a second SAN. Many customers use older-generation servers, enabling them to establish a standby environment for a fraction of the production price. IOprotect is priced for the use case and is up to 80% less expensive than VMware.
Once the minor disaster recovery environment is established, customers can use IOprotect to replicate an instance to the DR site, which also benefits from the same efficiency and lowers the cost of preparing for a major disaster. Organizations can use IOprotect just for protection from major disasters, but its cost-effectiveness makes protecting against minor disasters simple and affordable. It executes near-realtime data protection, making immutable, space-efficient snapshot copies of production data locally and then replicating it to a remote DR site.
No matter the failure, VergeOS with IOprotect enables rapid recovery. It is a complete disaster recovery solution, not just storage. All capabilities, storage, networking, and computing are available on the second minor and third remote DR instances. It also lays the groundwork for a VMware Exit if you decide to reduce costs further and increase the capabilities of the production environment. With VergeOS, you can lower your infrastructure costs by more than 70% and extend its life by years.